 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCREW: Computation Reuse and Efficient Weight Storage for Hardware-accelerated MLPs and RNNs
Jul 20, 2021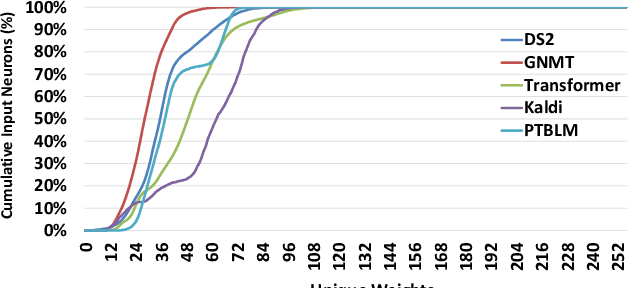
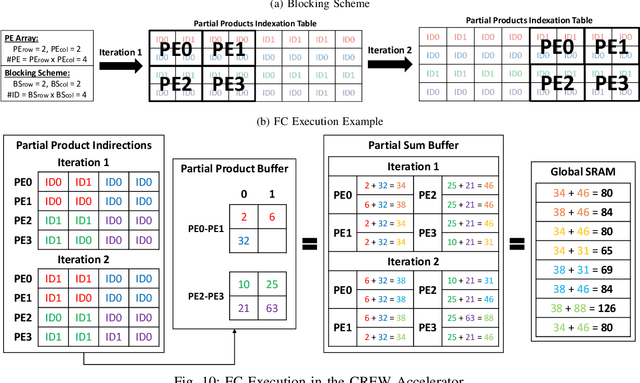
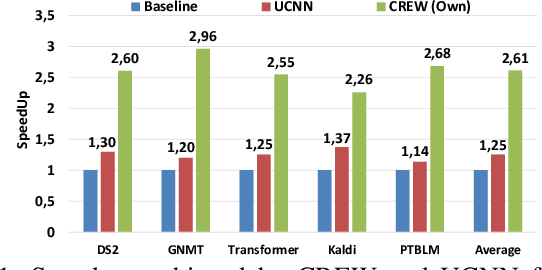
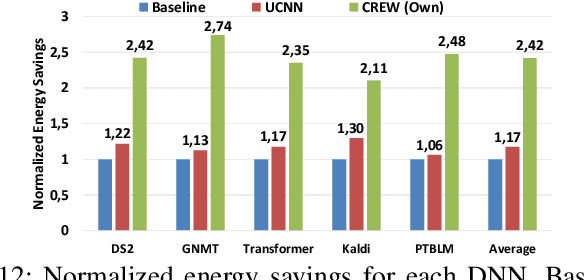
Deep Neural Networks (DNNs) have achieved tremendous success for cognitive applications. The core operation in a DNN is the dot product between quantized inputs and weights. Prior works exploit the weight/input repetition that arises due to quantization to avoid redundant computations in Convolutional Neural Networks (CNNs). However, in this paper we show that their effectiveness is severely limited when applied to Fully-Connected (FC) layers, which are commonly used in state-of-the-art DNNs, as it is the case of modern Recurrent Neural Networks (RNNs) and Transformer models. To improve energy-efficiency of FC computation we present CREW, a hardware accelerator that implements Computation Reuse and an Efficient Weight Storage mechanism to exploit the large number of repeated weights in FC layers. CREW first performs the multiplications of the unique weights by their respective inputs and stores the results in an on-chip buffer. The storage requirements are modest due to the small number of unique weights and the relatively small size of the input compared to convolutional layers. Next, CREW computes each output by fetching and adding its required products. To this end, each weight is replaced offline by an index in the buffer of unique products. Indices are typically smaller than the quantized weights, since the number of unique weights for each input tends to be much lower than the range of quantized weights, which reduces storage and memory bandwidth requirements. Overall, CREW greatly reduces the number of multiplications and provides significant savings in model memory footprint and memory bandwidth usage. We evaluate CREW on a diverse set of modern DNNs. On average, CREW provides 2.61x speedup and 2.42x energy savings over a TPU-like accelerator. Compared to UCNN, a state-of-art computation reuse technique, CREW achieves 2.10x speedup and 2.08x energy savings on average.
E-BATCH: Energy-Efficient and High-Throughput RNN Batching
Sep 22, 2020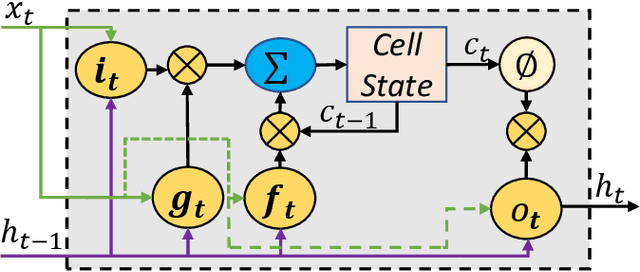
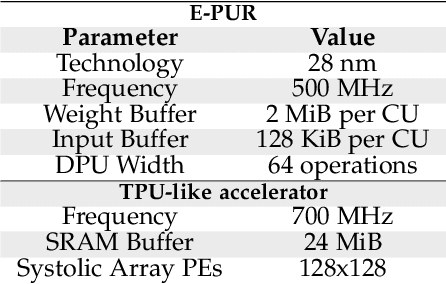
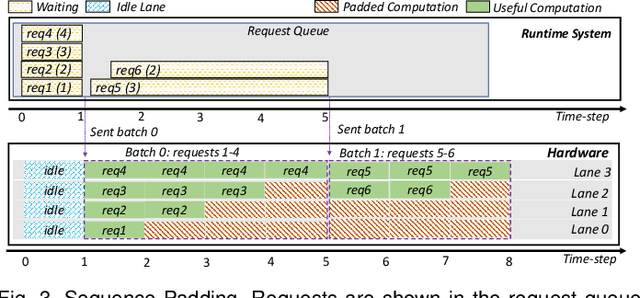
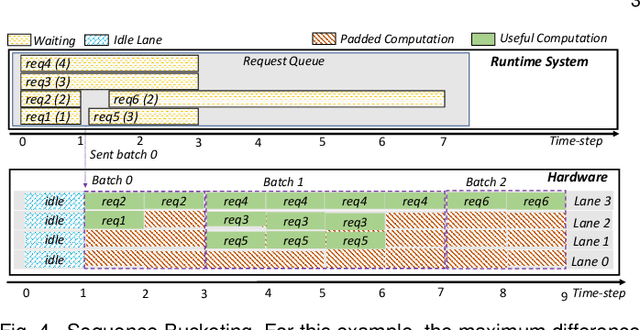
Recurrent Neural Network (RNN) inference exhibits low hardware utilization due to the strict data dependencies across time-steps. Batching multiple requests can increase throughput. However, RNN batching requires a large amount of padding since the batched input sequences may largely differ in length. Schemes that dynamically update the batch every few time-steps avoid padding. However, they require executing different RNN layers in a short timespan, decreasing energy efficiency. Hence, we propose E-BATCH, a low-latency and energy-efficient batching scheme tailored to RNN accelerators. It consists of a runtime system and effective hardware support. The runtime concatenates multiple sequences to create large batches, resulting in substantial energy savings. Furthermore, the accelerator notifies it when the evaluation of a sequence is done, so that a new sequence can be immediately added to a batch, thus largely reducing the amount of padding. E-BATCH dynamically controls the number of time-steps evaluated per batch to achieve the best trade-off between latency and energy efficiency for the given hardware platform. We evaluate E-BATCH on top of E-PUR and TPU. In E-PUR, E-BATCH improves throughput by 1.8x and energy-efficiency by 3.6x, whereas in TPU, it improves throughput by 2.1x and energy-efficiency by 1.6x, over the state-of-the-art.
LSTM-Sharp: An Adaptable, Energy-Efficient Hardware Accelerator for Long Short-Term Memory
Nov 04, 2019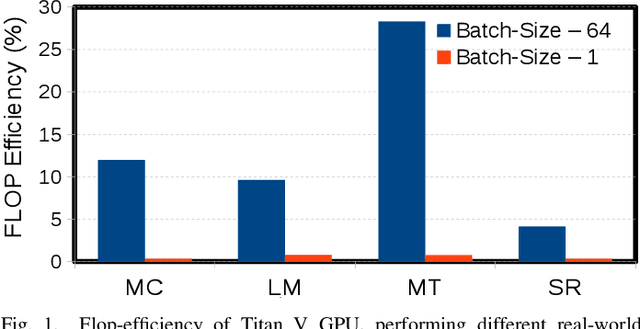
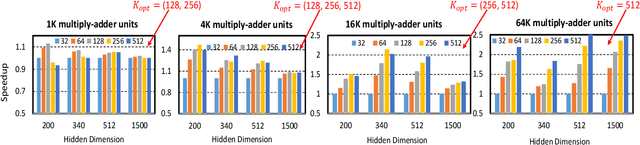
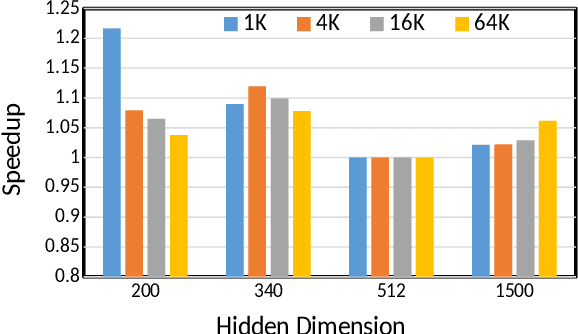
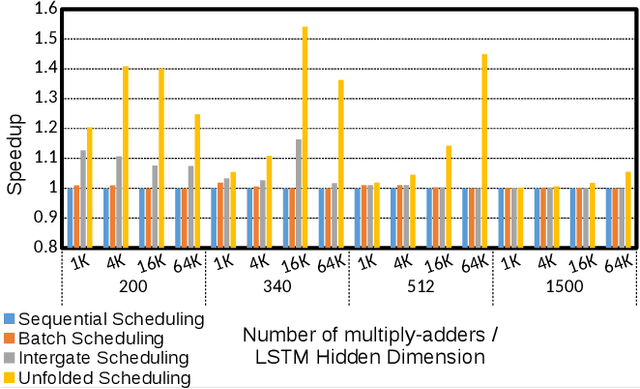
The effectiveness of LSTM neural networks for popular tasks such as Automatic Speech Recognition has fostered an increasing interest in LSTM inference acceleration. Due to the recurrent nature and data dependencies of LSTM computations, designing a customized architecture specifically tailored to its computation pattern is crucial for efficiency. Since LSTMs are used for a variety of tasks, generalizing this efficiency to diverse configurations, i.e., adaptiveness, is another key feature of these accelerators. In this work, we first show the problem of low resource-utilization and adaptiveness for the state-of-the-art LSTM implementations on GPU, FPGA and ASIC architectures. To solve these issues, we propose an intelligent tiled-based dispatching mechanism that efficiently handles the data dependencies and increases the adaptiveness of LSTM computation. To do so, we propose LSTM-Sharp as a hardware accelerator, which pipelines LSTM computation using an effective scheduling scheme to hide most of the dependent serialization. Furthermore, LSTM-Sharp employs dynamic reconfigurable architecture to adapt to the model's characteristics. LSTM-Sharp achieves 1.5x, 2.86x, and 82x speedups on average over the state-of-the-art ASIC, FPGA, and GPU implementations respectively, for different LSTM models and resource budgets. Furthermore, we provide significant energy-reduction with respect to the previous solutions, due to the low power dissipation of LSTM-Sharp (383 GFLOPs/Watt).
(Pen-) Ultimate DNN Pruning
Jun 06, 2019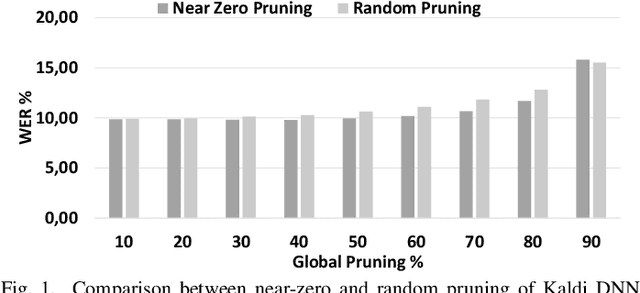
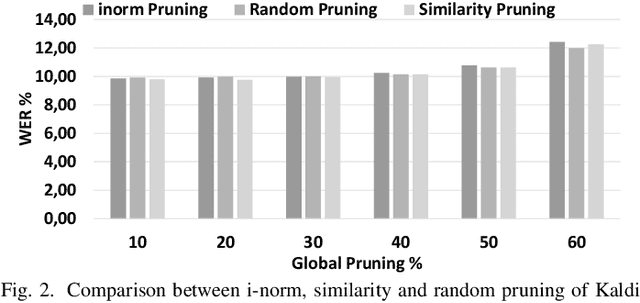
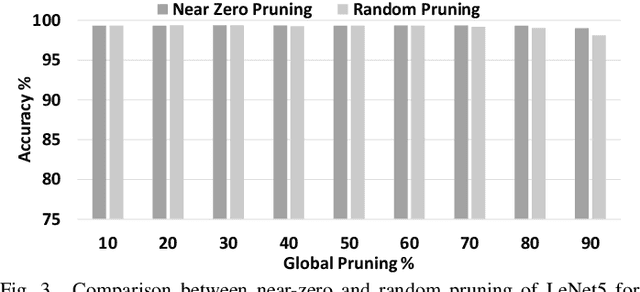
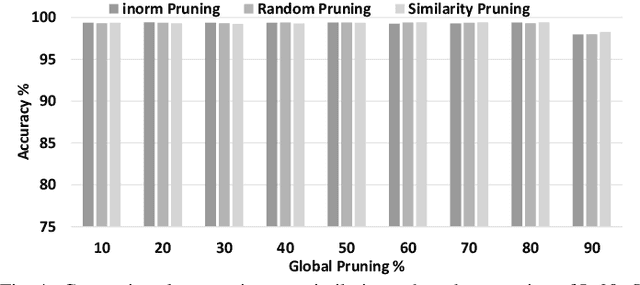
DNN pruning reduces memory footprint and computational work of DNN-based solutions to improve performance and energy-efficiency. An effective pruning scheme should be able to systematically remove connections and/or neurons that are unnecessary or redundant, reducing the DNN size without any loss in accuracy. In this paper we show that prior pruning schemes require an extremely time-consuming iterative process that requires retraining the DNN many times to tune the pruning hyperparameters. We propose a DNN pruning scheme based on Principal Component Analysis and relative importance of each neuron's connection that automatically finds the optimized DNN in one shot without requiring hand-tuning of multiple parameters.
E-PUR: An Energy-Efficient Processing Unit for Recurrent Neural Networks
Nov 20, 2017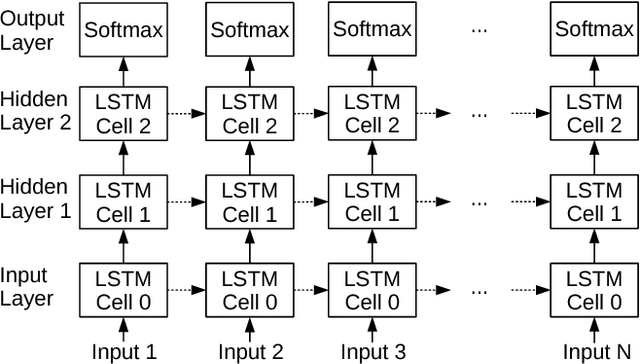

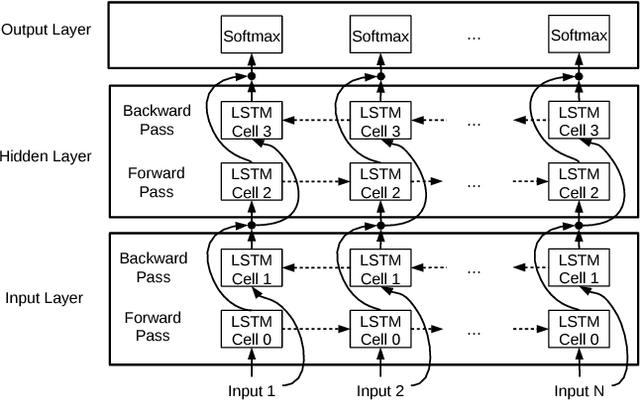
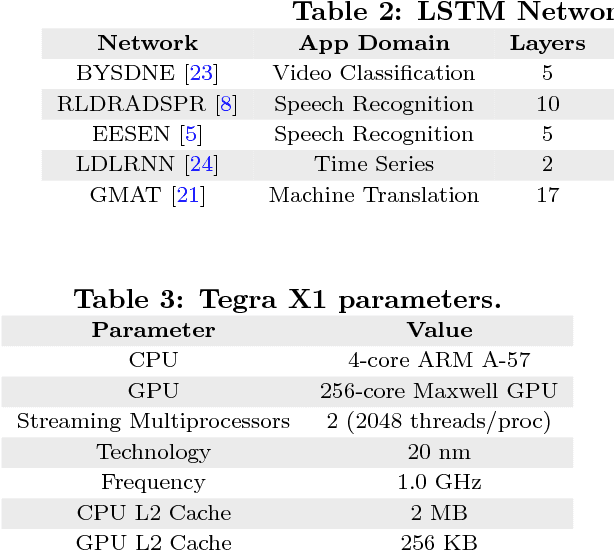
Recurrent Neural Networks (RNNs) are a key technology for emerging applications such as automatic speech recognition, machine translation or image description. Long Short Term Memory (LSTM) networks are the most successful RNN implementation, as they can learn long term dependencies to achieve high accuracy. Unfortunately, the recurrent nature of LSTM networks significantly constrains the amount of parallelism and, hence, multicore CPUs and many-core GPUs exhibit poor efficiency for RNN inference. In this paper, we present E-PUR, an energy-efficient processing unit tailored to the requirements of LSTM computation. The main goal of E-PUR is to support large recurrent neural networks for low-power mobile devices. E-PUR provides an efficient hardware implementation of LSTM networks that is flexible to support diverse applications. One of its main novelties is a technique that we call Maximizing Weight Locality (MWL), which improves the temporal locality of the memory accesses for fetching the synaptic weights, reducing the memory requirements by a large extent. Our experimental results show that E-PUR achieves real-time performance for different LSTM networks, while reducing energy consumption by orders of magnitude with respect to general-purpose processors and GPUs, and it requires a very small chip area. Compared to a modern mobile SoC, an NVIDIA Tegra X1, E-PUR provides an average energy reduction of 92x.